
Introduction
Kubernetes 환경에서의 Istio DNS Proxy 사용에 대한 설명으로, 이를 사용하면 CoreDNS를 포함한 DNS server로의 호출이 대폭 줄어든다. 이는 DNS server로의 부하 감소 뿐 아니라 app의 응답 속도 개선으로 이어진다. References 은 참조 문서다.
Motivation
Istio의 DNS Proxying을 눈여겨 보게된 동기는 Nodelocal DNSCache에 대한 대체 가능성 때문이다. 용도가 중복된다면 굳이 둘 모두를 운용할 필요가 없다.
Nodelocal DNSCache는 CoreDNS로의 부하 감소를 위한 DaemonSet로 동작하는 추가 패키지인데, 이 부하는 iptables 모드의 kube-proxy 환경에서 DNS lookup 실패를 유발한다. Appendix: conntrack race condition과 해결안 은 이에 대한 상세이다.
Summary
•
Istio DNS Proxying은 DNS roundtrip을 제거함으로 응답 속도 개선을 이룰 뿐 아니라 CoreDNS에 대한 부하를 급격히 제거한다.
•
Istio proxy는 미리 sync한 Kubernetes Service, Pod 및 Istio ServiceEntry 내 주소를 통해 투명하게(즉, app 변경 없이) DNS 서비스를 이룬다. 나머지 주소에 대해서는 관여하지 않아 일반적 DNS lookup 경로를 그대로 따른다.
•
이외에도 DNS server 변경 없이 DNS를 추가 가능하거나, 자동으로 virtual IP를 할당함으로 외부 TCP 서비스(e.g. AWS RDS)를 이슈 없이 식별 가능해진다.
Istio DNS Proxying 구조
Istio DNS proxying의 기본 아이디어는 “Istio가 가진 주소 정보 활용”인 듯 보인다. Istio proxy에는 이미 DNS 서비스에 필요한 Domain Name과 VIP(virtual IP - service IP), RIP(real IP - pod IP)가 있기 때문이다.
이를 고려하면 적어도 in-cluster 연산에는 CoreDNS 호출 필요성이 아예 사라진다. 해당 호출이 사라지므로 성능 증대는 물론 CoreDNS에 대한 부하를 (공식 문서 표현에 따르면) ‘drastically’ 완화하여, 이는 pod가 많아질 수록 더욱 그렇다.
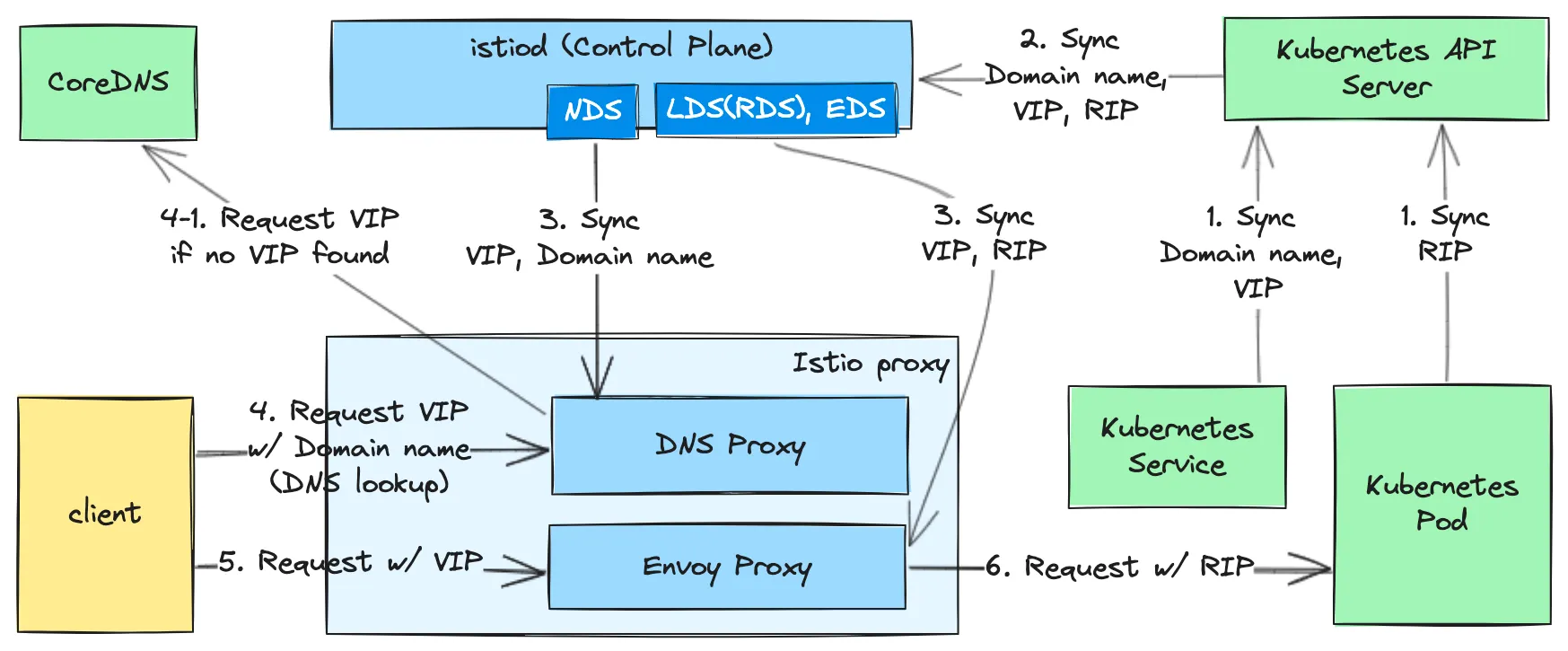
Istio DNS Proxying 구조
윗 그림은 Istio DNS proxying 구조로, DNS Proxying에 필요한 Domain name, VIP, RIP가 어떻게 sync되고 사용되는지를 나타낸다. 각 번호는 동작 순서로 1~3은 이들 정보에 대한 sync 과정, 4 ~ 6 부터는 사용 과정이다.
1.
Service / Pod → API Server: Kubernetes API Server는 Service와 Domain name, VIP를, Pod와 RIP를 sync한다(DNS 맥락 설명 집중을 위해 내부 구조를 추상화했다).
2.
3.
istiod → Istio proxy:  Istio Internals: xDS 참조. 추가로 istiod는 Kubernetes 뿐 아니라 Istio ServiceEntry 를 통한 Kubernetes 외부의 Domain Name, IP도 함께 보유한다. 이 역시 sync 대상이다.
Istio Internals: xDS 참조. 추가로 istiod는 Kubernetes 뿐 아니라 Istio ServiceEntry 를 통한 Kubernetes 외부의 Domain Name, IP도 함께 보유한다. 이 역시 sync 대상이다.
Istio Internals: xDS 참조. 추가로 istiod는 Kubernetes 뿐 아니라 Istio ServiceEntry 를 통한 Kubernetes 외부의 Domain Name, IP도 함께 보유한다. 이 역시 sync 대상이다.4.
client DNS lookup: client는 별도 수정 없이 DNS lookup을 수행한다. 이 때 DNS Proxy는 투명하게 해당 요청을 가로채서 VIP를 응답한다.
•
VIP가 없을 경우 원래의 설정(e.g. CoreDNS 호출)에 따라 DNS lookup 과정을 거친다. 다만 DNS lookup 결과의 caching 여부는 확인되지 않았는데, 자세한 내용은 를 참고한다.
5.
Request w/ VIP: #4에서 얻은 VIP로 request를 보낸다.
6.
Request w/ RIP: #5의 request을 가로챈 Envoy Proxy는 LB 과정을 통해 VIP에 해당하는 RIP를 식별하여 pod로 request를 보낸다.
DNS Proxy는 오직 sidecar에만 적용
Gateway instance(Ingress + API Gateway = Kubernetes Gateway API 참조) 확인 결과, 3번 실선 이후 Envoy Proxy에서의 VIP → RIP 변환에 필요한 VIP는 sidecar instance와는 달리 Envoy proxy에 없다. NDS config(/debug/ndsz debug API 호출로 확인) 역시 {} 로 비어있다.
Ingress + API Gateway = Kubernetes Gateway API 참조) 확인 결과, 3번 실선 이후 Envoy Proxy에서의 VIP → RIP 변환에 필요한 VIP는 sidecar instance와는 달리 Envoy proxy에 없다. NDS config(/debug/ndsz debug API 호출로 확인) 역시 {} 로 비어있다.Sidecar에만 적용되는 DNS proxying에 대한 Istio community에서의 cross check 결과
이외의 Istio DNS Proxy의 가치
•
DNS server 변경 없이 DNS 추가: DNS server에 등록되지 않은 domain에 대해, DNS server 업데이트 없이도 DNS 서비스가 가능하다. 해당 domain name과 IP를 Istio ServiceEntry 에 등록하면 되는데, 앞서 논했듯 DNS proxy는 ServiceEntry 내의 Domain Name, IP도 함께 보유하기 때문이다.
•
Automatic VIP allocation: 동일 port를 사용하는 다수의 외부 TCP endpoint(e.g. Amazon RDS)를 ServiceEntry 로 등록할 경우, 임의로 VIP(class E; non-routable)를 각 endpoint에 부여하여 0.0.0.0 이 아닌 해당 VPC를 기반으로 listener를 등록한다.
이게 없으면 0.0.0.0 의 단일 listener에 임의의 단일 TCP endpoint만 route로 등록되는 사태(?)가 발생하므로, ServiceEntry.spec.resolution 에 DNS 대신 None 을 사용하는 우회책이 요구된다. 하지만 이 우회책 역시 해당 endpoint의 IP 대신 모든 IP에 대해 outbound가 열리는 부작용을 유발한다. 이 말은 egress filtering (REGISTRY_ONLY 모드; 보안성 증대 등 용도)을 사용할 경우 보안 취약점이 된다는 뜻이다.
DNS Proxying 설정 방법
meshConfig 내 아래와 같이 두 가지 flag 설정으로 끝이다.
meshConfig:
...
defaultConfig:
...
proxyMetadata:
# Enable basic DNS proxying
ISTIO_META_DNS_CAPTURE: "true"
# Enable automatic VIP allocation, optional.
# ISTIO_META_DNS_AUTO_ALLOCATE: "true" 주석 처리한 이유는 아래 callout 참고
YAML
복사
2025.03.18 추가
상기 proxyMetadata 옵션에 automatic VIP allocation을 위한 ISTIO_META_DNS_AUTO_ALLOCATE 이 있었으나, PILOT_ENABLE_IP_AUTOALLOCATE 란 옵션으로 version 1.23에서 대체되었다. 여러 개선이 있던 듯 한데, 내 경우 이를 넣을 경우 TCP traffic이 식별 안되었다(tested in version 1.22.1).


version 1.25에서는 이전 옵션이 제거되고 새로운 옵션이 default가 되었다.


Appendix: DNS caching에 관하여
ServiceEntry 로 등록된 외부 서비스의 경우, resolution: DNS 타입을 사용 시 해당 DNS는 caching되어 매 30초마다 갱신된다(변경 불가. STATIC 타입은 해당 타입 속성 상 갱신 논외).


반면, ServiceEntry 로 등록되지 않은 외부 서비스의 DNS를 caching한다는 문서는 확인되지 않았고, 실험 결과 해당 lookup 결과가 NDS에 반영되지도 않았다. 이는 어쩌면 당연한게 ServiceEntry 로 등록되지 않은 외부 서비스는 Istio 관리 밖임이 명시되기 때문이다.
다만 Envoy는 이를 지원한다고 명시하며 이를 위한 configs(e.g. CaresDnsResolverConfig)도 Istio proxy에 설정되어 있음을 확인했지만, 정작 실험에서는 DNS lookup 결과가 확인 안되었다.
실험 방법은 Kubernetes, ServiceEntry에 등록되지 않은 외부 서비스 호출 직후, /config_dump API를 통해 envoy configuration 내 해당 서비스의 domain name, IP 등이 남아있는지를 확인하는 것이었는데, 확인 방법이 잘못된 것인지도 모른다(All known hosts ≠ cache?).
아래는 사전에 알려지지 않은 DNS caching 지원을 명시한 Envoy의 문서이다.
Appendix: conntrack race condition과 해결안
아래 링크는 DNS lookup 실패의 주요 원인인 conntrack race condition에 대한 원인 분석과 해결안으로, 뒤에 이어지는 글은 이에 대한 요약이다.
•
발생 조건: UDP 및 동일 socket(port)으로 muti threading 등을 통해 (거의) 동시에 두 개 이상의 packet이 도달
•
원인: kube-proxy 내 netfilter 가 사용하는 conntrack은 일부 packet을 drop. 이는 호출 각각에 해당하는 conntrack 내 connection entry가 동일하여 이에 대한 race condition이 발생하기 때문. DNS lookup 실패는 위의 packet drop의 결과.
•
여러 해결안이 있음
◦
NodeLocal DNSCache(공식 문서 링크) 사용. UDP 대신 TCP를 사용으로 상기 race condition 조건을 회피(첨언: 이외에도 caching 기능으로 인해 발생 조건 만족 가능성이 사실 상 사라짐).
◦
kube-proxy 에 iptables 대신 IPVS를 사용. conntrack을 사용하지 않으므로 이 역시 이슈 조건을 회피.
◦
Cilium CNI 등 eBPF 기반 CNI 사용. conntrack 대신 BPF 및 BPF Map을 이용하기 때문이라는데 구체적 원리는 문서에서 밝히지 않음.









